Read the rest of the post ' ¿Quién responde ante un error de la IA? El reto de la RC Profesional '


En este artículo me gustaría abordar un problema de ciberseguridad que veo de manera recurrente en las empresas y que creo que los expertos no hemos sabido explicar bien (además, se trata de un tema ligado en parte al artículo sobre las métricas publicado el mes pasado). Hoy hablamos sobre el problema de los falsos positivos y su elevada proporción en el campo de la ciberseguridad.
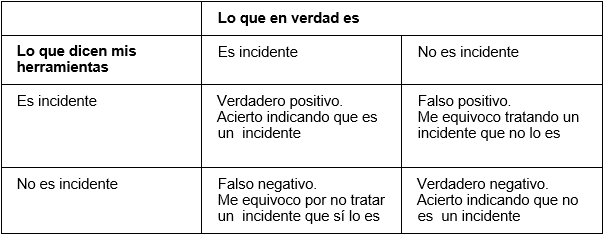
Pero, ¿qué es esto de un falso positivo? En cualquier herramienta de ciberseguridad, o en aquellas que realicen algún tipo de detección, podemos hablar de que existen cuatro estados del diagnóstico:
En la siguiente tabla, podemos ver que hay dos escenarios que deberíamos evitar: los escenarios de diagnóstico incorrecto, lo que en estadística se denominan los Errores Tipo I y Tipo II, siendo el falso positivo el error de Tipo I. A simple vista, es fácil ver que lo mejor sería eliminar los falsos positivos y falsos negativos y quedarnos sólo con los casos correctos. Pues bien, esto no es posible, ya que los errores son inversamente proporcionales, esto es, si quiero disminuir uno, estaré necesariamente incrementando el otro.
Veamos un ejemplo. Imaginemos que mi antivirus puede detectar amenazas de tres formas:
Si tengo configurado mi antivirus de una manera básica y veo que me estoy dejando muchas cosas sin detectar (falso negativo o error de tipo II), me plantearé subirle el nivel de configuración. Por tanto, si quiero que mi antivirus se salte menos incidentes, ajustaré de manera estricta estos parámetros de configuración, llegando a activar incluso los tres al mismo tiempo. Este nivel de configuración, lógicamente, va a considerar como casos positivos muchos más elementos. En este sentido, habrá ficheros que respondan a esos patrones de malware que no necesariamente lo son o, incluso, que el modelo experimental los asocie de manera errónea con malware y que sean reportados como tales. Al mejorar, con los casos de falsos negativos estoy, necesariamente, perjudicando los casos de falsos positivos.
Entendido este punto, la cuestión es: ¿por qué se ha priorizado en ciberseguridad que es mejor tener falsos positivos que falsos negativos? Pues no es algo exclusivo del campo de la ciberseguridad. De hecho, en los modelos de diagnósticos médicos sucede una situación similar y tiene que ver con el impacto asociado a equivocarnos. Veámoslo.
Entendamos primero el impacto de cometer un falso positivo: pongo en alerta a mi equipo de seguridad, aislamos la máquina “afectada”, realizamos las tareas de recuperación de disco por si posteriormente necesitamos hacer un análisis forense, analizamos el equipo en busca de la amenaza y (procedamos en el peor de los casos que no nos damos cuenta que no hay amenaza real) procedemos a limpiar y restaurar la máquina, cambiar las credenciales del usuario afectado y dejar registro del incidente. Costoso, ¿verdad? Pero vayamos al impacto de un falso negativo.
Un falso negativo implica que hay un sistema infectado pero no lo sabemos. El primer día el virus infecta ese sistema. Como no hay nada que se lo impida, tiene tiempo suficiente de probar diferentes ataques dentro del mismo sistema y de estudiar nuestra red de la empresa para aprender de ella. Finalmente, consigue unas credenciales de usuario válidas. Las exfiltra junto con toda la información que posee ese usuario. Con esas credenciales, empieza a probar vulnerabilidades internas de otros sistemas a los que puede llegar desde el infectado. Finalmente, da con una que le funciona y salta de sistemas.
Cogiendo el mejor escenario, en esta ocasión, le detectamos en este momento. Ponemos en alerta al equipo, aislamos las dos máquinas infectadas, etc…Se entiende el patrón, ¿verdad? Es decir, un falso negativo, cuando en el mejor de los casos lo descubramos, conllevará, seguramente, el mismo esfuerzo de eliminación que tendríamos con un falso positivo, pero seguramente sea peor por el tiempo que ha podido estar la máquina infectada o debido a otras variables. Y esto asumiendo que, más o menos, controlamos el impacto de la amenaza. Que si se trata de un ransomware de los fuertes puede llegar a poner en jaque a la empresa.
Con estos ejemplos espero que se entienda un poco mejor por qué en el mundo de la ciberseguridad se ha preferido pecar por exceso de prudencia. Pero, antes de finalizar, me gustaría que se entendiese que, aunque esto tenga sentido, lógicamente también se gastan recursos en tratar falsos positivos, por lo que, los que nos dedicamos a este campo, tenemos que hacer nuestros propios deberes al respecto y afinar mejor todos nuestros procesos y herramientas, intentando no comprometer su capacidad.
Espero, como siempre, que el artículo os haya acercado un aspecto nuevo de la ciberseguridad y, ¡nos vemos el próximo mes!




